
In a KNN model, we have to standardize data before sending the data to model.
Why do we have to do that?
Consider this data :

In the data above, Age is in years and Income is in rupees, in lakhs. Now, if we calculate Euclidean distance between 2 data points, it will be very high because of very high values in income. So Euclidean distance is more biased to a variable with higher magnitude. That variable is more reflected in our distance. Lets look at that :


See that the high magnitude of income is starkly shown in our Euclidean distance. We do not want our distance to be influenced/biased by high magnitude variables.
To overcome this problem, we bring down all variables to the same scale. This is done in our case by calculating Z score/ Mean centring our data. For every data point, we subtract its mean and divide by standard deviation.
#JustFYI This tells us about how many standard deviations away from mean is our data point.

There are other ways to standardise data. Not covering them here.
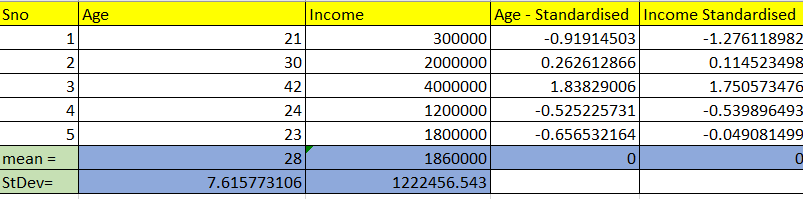
The Above table ahs mean centered data which will be used to train and test our KNN model.
Lets calculate distance for the same.

In this case we can clearly see that the distance is not biased.
It is always advisable to standardize the data before passing through a KNN model. The thumb rule is, If a model deals with distance, standardize data.
Questions:
- Why are we calling it mean centered data? (Hint: Look at the tables) . Will be happy to see your answers. Comment Below!
Happy Learning!
